Java NIO
关于对于 NIO笔记(一)基础内容的总结
若有疑问,去 https://aistudio.google.com/prompts/1gGBqWswXZKAtq8zdF5p8HRi6prHlseRa 查看/提问
NIO 是 Non-blocking I/O(非阻塞 IO)或者 New I/O(新 IO)的缩写。它是 Java 提供的一套用来处理输入输出的 API,与我们之前可能在 Java SE 或 Web 阶段学到的传统 IO(比如 FileInputStream, ServerSocket)不同。
核心区别:
- 传统 IO (阻塞 IO):当你调用一个读写操作时,如果数据还没准备好(比如,网络上对方还没发数据过来,或者你要写的文件暂时无法写入),你的程序就会停在那里一直等,直到操作完成。这叫做“阻塞”。
- NIO (非阻塞 IO):当你调用一个读写操作时,如果数据还没准备好,它会立刻告诉你“现在没数据”或者“暂时写不了”,然后你的程序可以继续干别的事情,过一会儿再来问问看好了没。这叫做“非阻塞”。
这种非阻塞的特性对于需要同时处理大量连接(比如成千上万个客户端)的网络服务器来说至关重要,因为服务器不能因为等待某一个客户端而卡住,耽误了处理其他客户端。
NIO 主要围绕着三个核心组件构建:Buffer(缓冲区)、Channel(通道) 和 Selector(选择器)。我们一个一个来看。
Buffer (缓冲区)
你可以把 Buffer 想象成一个带有额外管理功能的数组,或者一个智能的“桶”。它是 NIO 中用来临时存放数据的主要容器。无论你是要从文件/网络读取数据,还是要把数据写入文件/网络,数据都需要先经过 Buffer 中转。
核心概念详解:
-
四个核心变量/指针: 这是理解 Buffer 操作的关键。
capacity(容量):Buffer 能容纳的总数据量(单位是它存储的数据类型,比如IntBuffer就是 int 的数量)。一旦创建,容量是固定不变的。(桶的总容积)limit(限制):- 在读模式下(从 Buffer 往外读数据),
limit表示你最多能读到哪个位置,也就是有效数据的末尾。 - 在写模式下(往 Buffer 里写数据),
limit通常等于capacity,表示你最多可以写到哪个位置。 - 你不能读写超过
limit的位置。(读模式下:桶里实际的水位线;写模式下:你打算最多把水加到哪里,通常是桶口)
- 在读模式下(从 Buffer 往外读数据),
position(位置):表示下一个要被读取或写入的元素的位置(索引)。每次调用get()(读) 或put()(写) 之后,position会自动向后移动。(你当前正准备从哪个位置倒水,或者往哪个位置加水)mark(标记):一个临时的书签。你可以调用mark()方法记住当前的position,之后可以通过调用reset()方法将position恢复到之前标记的位置。(在桶壁上某个水位画个记号)- 它们的关系恒定:
0 <= mark <= position <= limit <= capacity。
-
Buffer 的种类与创建:
- Java 为大部分基本数据类型(除了
boolean)都提供了对应的 Buffer 类:ByteBuffer,CharBuffer,IntBuffer,ShortBuffer,LongBuffer,FloatBuffer,DoubleBuffer。其中ByteBuffer是最常用的,因为文件和网络传输的底层数据通常是字节。 - 创建方式 (不用
new):Buffer类名.allocate(capacity):创建一个指定容量的空 Buffer。这个 Buffer 的数据实际存储在 Java 堆内存的一个数组里。这被称为“堆缓冲区”(Heap Buffer)。(造一个新的空桶)Buffer类名.wrap(现有数组):用一个已经存在的数组来创建一个 Buffer。这个 Buffer 直接使用这个数组来存数据,不会复制一份。所以,修改 Buffer 里的数据,会直接改变原数组;反之亦然。(直接拿一个现成的装满东西的数组,给它套上 Buffer 的管理功能)
- Java 为大部分基本数据类型(除了
-
写入数据 (put 操作): 往 Buffer 里放数据。
buffer.put(数据):在当前的position位置放入数据,然后position加 1。buffer.put(索引, 数据):在指定的索引位置放入数据,不会改变当前的position。buffer.put(数组)或buffer.put(数组, offset, length):将源数组中的数据(全部或部分)批量复制到 Buffer 中,从 Buffer 的当前position开始放,并相应地移动position。buffer.put(另一个Buffer):将另一个 Buffer 中剩余未读的数据复制到当前 Buffer 中。
-
至关重要的
flip()方法:- 为什么需要它? 当你用
put方法向 Buffer 中写完数据后,position指向的是你刚写入数据的后面,而limit很可能还是等于capacity。这时,如果你想读取你刚刚写入的数据,你需要做两件事:- 告诉 Buffer 读取操作应该在哪里结束,也就是你实际写入数据的末尾。这个末尾就是你写完数据后的
position。 - 将读取的起始位置设置回 Buffer 的开头(索引 0)。
- 告诉 Buffer 读取操作应该在哪里结束,也就是你实际写入数据的末尾。这个末尾就是你写完数据后的
flip()做了什么? 它正是帮你完成这两件事:limit = position; position = 0; mark = -1;(把limit设置为当前position,再把position归零,同时清除mark标记)。- 比喻: 你往桶里加水(
put),加到一定水位后停下(此时position在水位线)。现在你想把桶里的水倒出来(get)。flip()操作就像是:1. 在当前水位线那里给桶加了个盖子(limit = position),防止倒水时超过这个水位。2. 把倒水的起点设置回桶底(position = 0)。
- 为什么需要它? 当你用
-
读取数据 (get 操作): 从 Buffer 里取数据。
buffer.get():读取当前position位置的数据,然后position加 1。buffer.get(索引):读取指定索引位置的数据,不会改变当前的position。buffer.get(目标数组)或buffer.get(目标数组, offset, length):将 Buffer 中的数据(从当前position开始)批量复制到目标数组中,并相应地移动position。remaining():返回limit - position,告诉你还有多少数据可以读取。hasRemaining():检查是否还有数据可读 (position < limit)。经常用在循环中:while(buffer.hasRemaining()) { 处理(buffer.get()); }
-
其他常用方法:
rewind():position = 0; mark = -1;。limit不变。让你能重新从头读取 Buffer 中的数据(前提是你之前已经flip()过了)。(把倒水的起点移回桶底,准备重新倒一遍)clear():position = 0; limit = capacity; mark = -1;。让 Buffer 准备好重新写入数据。它并不会真的清除 Buffer 里的旧数据,只是把指针复位了,后续写入会覆盖旧数据。(把桶“清空”——其实水还在,但把水位标记和倒水位置都重置了,看起来像空桶一样,可以重新加水了)compact():将所有未读的数据(从position到limit之间的数据)移动到 Buffer 的开头。然后,position设置为这些移动后数据的末尾,limit设置为capacity。这在你读取了一部分数据,又想继续往 Buffer 里写新数据,但不想覆盖掉还没读的那部分数据时很有用。(把桶里没倒完的水,都集中到底部,然后把加水的位置设在这些水之上,准备继续加水)mark()&reset():前面提过,设置和恢复书签。duplicate():创建一个新的 Buffer 对象,但这个新 Buffer 和原始 Buffer 共享同一个底层数组(或者同一块内存区域)。它们各自拥有独立的position,limit,mark状态。但是,如果你通过一个 Buffer 修改了数据(例如buffer1.put(0, 100)),那么通过另一个 Buffer 读取相同位置的数据(例如buffer2.get(0))会看到这个修改。(像是给同一个桶,贴了两套不同的水位标记和读写位置指示器,但操作的都是同一个桶里的水)slice():创建一个新的 Buffer,它代表原始 Buffer 的一个子序列(从原始 Buffer 的position到limit)。它也共享底层数据,但拥有自己独立的、从 0 开始计算的position,limit,mark。(像是从大桶里划出一块区域,给这块区域单独一套标记,但操作的还是大桶里那部分水)
-
只读缓冲区 (Read-Only Buffers):
- 通过
原buffer.asReadOnlyBuffer()创建。它也是共享底层数据的,但是如果你尝试对这个只读 Buffer 调用任何put方法,它会抛出ReadOnlyBufferException异常。这是一种保护机制,用来安全地传递数据而不允许接收方修改它。
- 通过
-
ByteBuffer 和 CharBuffer 的特性:
ByteBuffer:非常基础和常用。它可以直接存取其他基本类型的数据(如putInt(),getInt(),putDouble(),getDouble()等)。你需要注意字节序(大端/小端),不过通常默认设置(大端)能满足大部分需求。CharBuffer:专门用于处理字符数据。可以直接存取String(put("字符串"),wrap("字符串"))。它实现了CharSequence接口,所以可以用很多类似String的方法,比如charAt(),subSequence(),甚至可以直接打印CharBuffer对象(会自动调用toString()输出内容)。
-
直接缓冲区 (Direct Buffers):
- 创建: 使用
ByteBuffer.allocateDirect(capacity)。 - 是什么: 它申请的内存不在 Java 的常规堆内存(Heap)中,而是在堆外的本地内存(Native Memory)中。
- 为什么用: 对于某些底层的 IO 操作(如网络发送、文件读写),操作系统可能可以直接操作这块本地内存,避免了一次从 Java 堆内存到本地内存的数据复制,从而可能提高性能。
- 工作原理 (简化版): 内部使用了 Java 的一些底层、非标准的机制(如
sun.misc.Unsafe类)来直接向操作系统申请和释放内存。 - 垃圾回收: 因为内存不在 Java 堆上,普通的 GC 无法直接管理。NIO 使用了一种叫做
Cleaner的机制,它与 Java 的虚引用(PhantomReference) 配合工作。当创建DirectByteBuffer的 Java 对象不再被任何地方引用,即将被 GC 回收时,Cleaner会被触发,进而调用底层的Unsafe方法来释放之前申请的那块本地内存,防止内存泄漏。 - 共享与
att字段: 当你对一个DirectByteBuffer进行duplicate()或slice()操作时,产生的新的 Buffer 对象同样共享那块本地内存。文档中提到的att(attachment) 字段是一个内部实现细节,它的作用是让复制或切分出来的 Buffer 对象持有一个对原始 Buffer 对象(或者说持有对管理那块内存的对象的引用),确保即使原始的 Buffer 对象看似没有被引用了,只要还有复制品或切片在用,那块本地内存就不会被过早释放。
- 创建: 使用
Channel (通道)
你可以把 Channel 想象成连接数据源/目的地(比如文件、网络连接)和 Buffer(桶) 之间的管道。数据总是通过 Channel 从源流入 Buffer,或者从 Buffer 通过 Channel 流出到目的地。Channel 代表了与能够进行 IO 操作的实体(文件、套接字等)的连接。
核心概念详解:
-
Channel vs. Stream (流):
- 方向: Stream 通常是单向的(
InputStream只读,OutputStream只写)。Channel 通常是双向的(比如SocketChannel既可读也可写),但也有单向的(如FileChannel从FileInputStream获取时只读)。 - 数据单元: Stream 直接操作字节或字符。Channel 总是与 Buffer 配合使用,数据必须先读入 Buffer 或从 Buffer 写入。
- 方向: Stream 通常是单向的(
-
主要的接口:
Channel: 最基础的接口,定义了isOpen()(通道是否打开) 和close()(关闭通道)。ReadableByteChannel: 定义了int read(ByteBuffer dst)方法,从通道读取数据到目标 ByteBuffer。WritableByteChannel: 定义了int write(ByteBuffer src)方法,将源 ByteBuffer 中的数据写入通道。ByteChannel: 同时继承了ReadableByteChannel和WritableByteChannel,表示可读写的字节通道。SeekableByteChannel: 针对可以定位读写位置的通道(主要是文件)。增加了position()(获取或设置当前位置),size()(获取实体大小),truncate(long size)(截断实体到指定大小) 等方法。FileChannel实现了这个接口。InterruptibleChannel: 允许在一个线程阻塞于此通道的 IO 操作时,另一个线程可以通过调用close()方法来中断那个阻塞的线程(阻塞的线程会抛出AsynchronousCloseException)。
-
FileChannel (文件通道): 用于文件 IO。
- 获取方式:
- 通过
FileInputStream或FileOutputStream的getChannel()方法获取。这种方式得到的FileChannel会继承流的只读或只写属性。 - 通过
RandomAccessFile的getChannel()方法获取。如果RandomAccessFile是以"rw"(读写) 模式打开的,那么得到的FileChannel就既可读又可写,这是最常用的方式。
- 通过
- 常用操作:
read(ByteBuffer dst): 从文件的当前位置读取数据到 buffer。write(ByteBuffer src): 将 buffer 中的数据写入文件的当前位置。position()/position(long newPos): 获取或设置文件内的读写指针位置。size(): 获取文件当前的大小。truncate(long size): 将文件截断到指定的大小(超出部分被删除)。transferTo(long pos, long count, WritableByteChannel target): 高效地将本文件通道的数据(从pos开始,最多count字节)传输到目标通道。transferFrom(ReadableByteChannel src, long pos, long count): 高效地从源通道读取数据(最多count字节)并写入本文件通道的pos位置。这两个传输方法可能利用操作系统的“零拷贝”特性,非常高效。map(MapMode mode, long position, long size): 内存映射。将文件的一部分(从position开始,大小为size)直接映射到内存中,返回一个MappedByteBuffer(它是一种DirectByteBuffer)。你可以像操作内存数组一样操作这个 Buffer。如果mode是READ_WRITE,你对 Buffer 的修改最终会反映到磁盘文件上(但不一定是实时的)。调用buffer.force()可以强制将内存中的修改同步到磁盘。
- 获取方式:
-
FileLock (文件锁):
- 用途: 控制不同进程(独立运行的程序)之间对同一个文件(或文件的一部分)的访问。不是用来控制同一个程序内部多个线程访问文件的。主要目的是防止多个程序同时修改文件导致数据损坏。
- 获取锁:
channel.lock(position, size, shared): 尝试获取锁。如果锁已被其他进程以冲突的方式持有,这个方法会阻塞,直到能获取锁为止。channel.tryLock(position, size, shared): 尝试获取锁,但不阻塞。如果能立刻获得锁,就返回FileLock对象;如果不能(比如已被其他进程锁定),就立刻返回null。
- 锁的类型:
- 独占锁 (Exclusive Lock,
shared = false): 同一时间,文件的某个区域只能被一个进程持有独占锁。持有者可以对该区域进行读写操作。其他任何进程都不能再对该区域获取任何锁(无论是独占还是共享)。 - 共享锁 (Shared Lock,
shared = true): 同一时间,文件的某个区域可以被多个进程同时持有共享锁。持有者只能进行读操作,不能写。它可以阻止其他进程获取该区域的独占锁,但不阻止其他进程获取共享锁。
- 独占锁 (Exclusive Lock,
- 注意事项: 文件锁在很多操作系统上是“建议性锁”,意味着如果程序不主动检查和遵守锁规则,它仍然可能绕过锁去访问文件。使用完锁后,必须调用
lock.release()释放锁,最好放在finally块中确保执行。要锁定整个文件,通常使用channel.lock(0, Long.MAX_VALUE, shared)。如果两个锁请求的区域有重叠,通常是不允许的(即使一个是共享,一个是独占)。
Selector (选择器) 与网络通信 (多路复用)
这是 NIO 在网络编程方面的核心优势所在,它让一个(或少数几个)线程能够高效地管理大量的网络连接。
核心概念详解:
-
传统阻塞 IO 的问题: 在网络编程中,传统的
ServerSocket.accept()(等待客户端连接) 和Socket.read()(等待客户端发数据) 都是阻塞的。如果服务器要同时处理很多客户端,一种常见做法是为每个客户端连接创建一个单独的线程。当客户端数量非常多时,即使很多客户端大部分时间是空闲的(没发数据),也需要保持大量的线程,这会消耗大量的内存和 CPU 资源,导致服务器性能下降或崩溃。 -
NIO 的非阻塞方案:
- 设置非阻塞模式: 首先,需要将网络相关的 Channel(
ServerSocketChannel,SocketChannel)设置为非阻塞模式:channel.configureBlocking(false)。 - 非阻塞行为: 设置后,
accept()和read()方法会立即返回。accept(): 如果正好有客户端连接请求进来,它返回代表这个连接的SocketChannel;如果没有,它返回null。read(): 如果通道里有数据可读,它读取数据并返回读取的字节数;如果没有数据可读,它返回 0;如果连接已关闭,它返回 -1。
- 新问题: 虽然不阻塞了,但程序怎么知道什么时候去调用
accept()或read()才能拿到有效连接或数据呢?不停地循环去问(轮询)会浪费 CPU。这时就需要Selector。
- 设置非阻塞模式: 首先,需要将网络相关的 Channel(
-
Selector (选择器):
- 比喻: 可以把它想象成一个事件通知中心、一个机场的塔台、或者一个能同时监控很多管道的看门人。
- 注册 (Register): 你需要把你的非阻塞 Channel "注册" 到 Selector 上,并且告诉 Selector 你对这个 Channel 的哪些事件感兴趣(比如,“当这个
ServerSocketChannel可以接受新连接时通知我”,或者“当这个SocketChannel有数据可读时通知我”)。这些感兴趣的事件用常量表示:SelectionKey.OP_ACCEPT: 对ServerSocketChannel有效,表示可以接受(accept)一个新的连接了。SelectionKey.OP_CONNECT: 对SocketChannel有效(客户端),表示连接操作(connect)完成了。SelectionKey.OP_READ: 对SocketChannel有效,表示通道里有数据可以读取(read)了。SelectionKey.OP_WRITE: 对SocketChannel有效,表示可以向通道写入(write)数据了。(这个事件比较特殊,因为通常通道都是可写的,所以如果一直监听它,可能会导致select()持续返回,需要谨慎使用)。
- 选择 (Select):
selector.select()是核心方法。它会阻塞在那里(或者阻塞一个设定的超时时间),直到至少有一个你注册过的 Channel 准备好了你感兴趣的事件。当有事件发生时,select()方法会返回,并告诉你有多少个 Channel 已经就绪。 - 获取就绪的 Key: 当
select()返回大于 0 的值时,你需要调用selector.selectedKeys()。这会返回一个Set<SelectionKey>集合,集合里的每一个SelectionKey都代表一个已经就绪的 Channel。 - SelectionKey: 这是 Channel、Selector 和事件之间的纽带。一个
SelectionKey对象包含了:- 对应的 Channel (
key.channel())。 - 对应的 Selector (
key.selector())。 - 你当初注册时感兴趣的事件集合 (
key.interestOps())。 - 当前 Channel 实际已经就绪的事件集合 (
key.readyOps())。你可以通过key.isAcceptable(),key.isReadable(),key.isWritable(),key.isConnectable()来检查具体是哪个事件就绪了。 - 一个可选的附加对象 (
key.attach(Object obj),key.attachment())。这个非常有用,你可以把与这个 Channel 相关的数据(比如用户会话信息、处理这个 Channel 的 Handler 对象等)附加到 Key 上,方便在处理事件时获取。
- 对应的 Channel (
-
事件循环 (Event Loop): 使用 Selector 的典型编程模式通常是一个无限循环:
Selector selector = Selector.open(); // ... 把 ServerSocketChannel 注册到 selector 上,监听 OP_ACCEPT ... serverChannel.register(selector, SelectionKey.OP_ACCEPT); while (true) { // 1. 等待事件发生 int readyChannels = selector.select(); if (readyChannels == 0) { continue; // 可能被唤醒或超时,但没事件,继续等 } // 2. 获取所有就绪事件的 SelectionKey Set<SelectionKey> selectedKeys = selector.selectedKeys(); Iterator<SelectionKey> keyIterator = selectedKeys.iterator(); while (keyIterator.hasNext()) { SelectionKey key = keyIterator.next(); // 3. 根据就绪的事件类型,进行处理 if (key.isAcceptable()) { // 处理新连接请求: // ServerSocketChannel server = (ServerSocketChannel) key.channel(); // SocketChannel client = server.accept(); // 把 client 设为非阻塞 // 把 client 注册到 selector 上,监听 OP_READ (通常) } else if (key.isReadable()) { // 处理客户端发来的数据: // SocketChannel client = (SocketChannel) key.channel(); // ByteBuffer buffer = ...; // client.read(buffer); // 处理 buffer 中的数据... } else if (key.isWritable()) { // 处理写就绪(如果需要): // SocketChannel client = (SocketChannel) key.channel(); // ByteBuffer buffer = ...; // 准备要写的数据 // client.write(buffer); } // 4. *** 非常重要:处理完一个 Key 后,必须从 selectedKeys 集合中移除它!*** keyIterator.remove(); } }- 为什么必须
keyIterator.remove()?select()方法只是把就绪的 Key 添加到selectedKeys集合中,它不会自动移除。如果你处理完一个事件后不把它从集合里移除,下一次select()返回时(即使这个 Channel 没有新的事件),这个 Key 仍然会在selectedKeys集合里,导致你重复处理同一个(可能已经处理过的)事件,引发逻辑错误。
- 为什么必须
-
底层的 IO 多路复用模型: 文档提到了
select,poll,epoll。这些是操作系统层面实现 IO 多路复用的技术。Java 的Selector在不同操作系统上会使用相应最高效的底层实现(比如在 Linux 上优先使用epoll)。epoll比select和poll更高效,因为它能精确地告诉你哪些连接就绪了(事件驱动,复杂度 O(1)),而select和poll需要遍历所有监听的连接来检查状态(复杂度 O(n))。Java NIO 的Selector帮我们屏蔽了这些底层差异。 -
Reactor 模式: 这是一种常用的设计模式,用来组织基于 Selector 的网络服务器程序结构,目的是分离职责,提高可维护性和可扩展性。
- 核心组件:
- Reactor: 通常在一个或多个专用线程中运行,负责监听事件 (
selector.select()),并将就绪的事件**分发(dispatch)**给对应的 Handler 处理。 - Handler/Acceptor: 负责处理具体的事件。
Acceptor通常专门处理连接建立事件 (OP_ACCEPT),Handler处理读写事件 (OP_READ,OP_WRITE) 和相关的业务逻辑。
- Reactor: 通常在一个或多个专用线程中运行,负责监听事件 (
- 几种变体:
- 单线程 Reactor: 一个线程负责
select()循环,并且直接在该线程中执行所有的 Handler(包括 Acceptor 和读写 Handler)。实现简单,但在 Handler 处理耗时较长时会阻塞整个 Reactor。 (文档中第一个 Reactor 示例) - 多线程 Reactor (使用 Worker 线程池): Reactor 线程只负责
select()和基本的 IO 操作(比如accept()或read()到 Buffer),然后将包含数据的 Buffer 或任务提交给一个独立的 Worker 线程池去执行耗时的业务逻辑处理和响应写入。这样 Reactor 线程能快速返回继续监听事件,提高了并发处理能力。 (文档中第二个 Reactor 示例) - 主从 Reactor (Main-Sub Reactor):
- Main Reactor (通常一个线程): 只负责监听和处理
ServerSocketChannel上的OP_ACCEPT事件。当接受一个新连接 (SocketChannel) 后,它不负责这个连接后续的读写。 - Sub Reactor (通常多个线程,比如每个 CPU 核心一个): 每个 Sub Reactor 都有自己独立的
Selector,负责处理一部分客户端连接 (SocketChannel) 上的OP_READ和OP_WRITE事件。 - 工作流程: Main Reactor 接受新连接后,通过某种策略(如轮询)选择一个 Sub Reactor,并将这个新的
SocketChannel注册到那个 Sub Reactor 的Selector上,监听OP_READ事件。这样,处理连接建立和处理数据读写的负载就被分散开了。 (文档中最后一个 Reactor 示例) selector.wakeup():当 Main Reactor 线程要把新接受的SocketChannel注册到某个 Sub Reactor 的Selector上时,因为注册操作发生在 Main Reactor 线程,而 Sub Reactor 的select()可能正在其自己的线程中阻塞等待。为了确保 Sub Reactor 能及时发现这个新注册的 Channel,需要在调用register()之前,调用一下 Sub Reactor 的selector.wakeup()方法。这会中断select()的阻塞,让它重新检查注册的 Channel。
- Main Reactor (通常一个线程): 只负责监听和处理
- 单线程 Reactor: 一个线程负责
- 核心组件:
总结一下:
- Buffer 是 NIO 中智能的数据容器,通过
position,limit等指针精 K 确管理数据读写状态,flip()是读写切换的关键。Direct Buffer 通过本地内存提供潜在性能优化。 - Channel 是连接数据源/目的地和 Buffer 之间的管道,用于传输数据。
FileChannel用于文件,SocketChannel/ServerSocketChannel用于网络。非阻塞模式是 NIO 网络编程的基础。 - Selector 是实现高并发网络服务器的核心,它允许单线程或少量线程管理大量非阻塞 Channel 的 IO 事件,通过
select()等待事件就绪,避免了为每个连接创建线程的开销。Reactor 模式是构建健壮 Selector 应用的常用架构。
对于 I/O 模型之间的对比&代码分析
理解 BIO、NIO 和 AIO 的区别。
NIO 相关代码分析
- BIO 为 Java 传统的 I/O 方式,在 java.io 包下
- AIO 为 Java.nio.channels.Asynchronous 包下(但 AIO 和 NIO 有一定关联,但只是 NIO 的扩展,并非完全继承在其中)
- 选择器实现了 I/O 多路复用
以一个简单的“服务器接收客户端消息并回显”的场景为例。
场景: 客户端连接服务器,发送一行文本,服务器收到后加上"Server received: "前缀再发回给客户端。
1. BIO (同步阻塞 IO) - 代码与分析
核心特点: 一个连接一个线程,API 调用阻塞。
// BioServer.java
import java.io.*;
import java.net.*;
import java.util.concurrent.*;
public class BioServer {
public static void main(String[] args) throws IOException {
// 1. 创建一个线程池来处理客户端连接,避免无限创建线程
// 虽然用了线程池,但本质还是一个连接对应一个活跃(或等待)线程
ExecutorService threadPool = Executors.newCachedThreadPool();
ServerSocket serverSocket = null;
try {
// 2. 创建 ServerSocket,监听 8080 端口
serverSocket = new ServerSocket(8080);
System.out.println("BIO Server started on port 8080, waiting for connections...");
while (true) { // 主线程循环,持续接受新连接
// 3. serverSocket.accept() 是一个【阻塞】方法
// 如果没有客户端连接,线程会一直卡在这里等待
final Socket clientSocket = serverSocket.accept();
System.out.println("Client connected: " + clientSocket.getRemoteSocketAddress());
// 4. 当有新连接进来时,将处理任务交给线程池中的一个线程
threadPool.execute(() -> {
handleClient(clientSocket); // 调用处理客户端逻辑的方法
});
}
} finally {
if (serverSocket != null) {
serverSocket.close();
}
threadPool.shutdown(); // 关闭线程池
}
}
// 处理单个客户端连接的方法
private static void handleClient(Socket clientSocket) {
// 5. 使用 try-with-resources 确保流和 Socket 能被正确关闭
try (InputStream in = clientSocket.getInputStream();
OutputStream out = clientSocket.getOutputStream();
// 6. 使用 BufferedReader 和 PrintWriter 简化文本读写
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
PrintWriter writer = new PrintWriter(out, true)) // true 表示自动 flush
{
String line;
// 7. reader.readLine() 是一个【阻塞】方法
// 如果客户端没有发送数据(或者没发送换行符),线程会卡在这里等待
while ((line = reader.readLine()) != null) {
System.out.println("Received from " + clientSocket.getRemoteSocketAddress() + ": " + line);
// 8. writer.println() 将数据写入缓冲区,可能也会阻塞(如果缓冲区满)
writer.println("Server received: " + line);
}
// 9. 当 readLine() 返回 null 时,表示客户端断开了连接(输入流结束)
System.out.println("Client disconnected: " + clientSocket.getRemoteSocketAddress());
} catch (IOException e) {
// 10. 处理读写过程中可能发生的异常
System.err.println("Error handling client " + clientSocket.getRemoteSocketAddress() + ": " + e.getMessage());
}
// try-with-resources 会自动关闭 clientSocket
}
}
// BioClient.java (用于测试)
import java.io.*;
import java.net.*;
import java.util.Scanner;
public class BioClient {
public static void main(String[] args) {
try (Socket socket = new Socket("localhost", 8080); // 连接服务器
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream())); // 读取服务器响应
PrintWriter writer = new PrintWriter(socket.getOutputStream(), true); // 向服务器发送数据
Scanner scanner = new Scanner(System.in)) // 读取用户输入
{
System.out.println("Connected to server. Enter messages (or 'quit' to exit):");
String userInput;
while (!(userInput = scanner.nextLine()).equalsIgnoreCase("quit")) {
writer.println(userInput); // 发送用户输入到服务器
String serverResponse = reader.readLine(); // 【阻塞】等待服务器响应
System.out.println("Server response: " + serverResponse);
}
} catch (IOException e) {
System.err.println("Client Error: " + e.getMessage());
}
System.out.println("Client disconnected.");
}
}
BIO 代码分析:
- 阻塞点: 代码中明确标出了
serverSocket.accept()和reader.readLine()是阻塞的。这意味着执行到这些行时,如果条件不满足(没有连接或没有数据),当前线程就会停止执行,让出 CPU,直到条件满足。 - 线程模型: 为了让服务器能同时处理多个客户端,必须为每个
accept()返回的Socket分配一个独立的线程(这里通过线程池管理)。如果有一万个连接,理论上就需要(或曾经需要)一万个线程,这对系统资源是巨大的负担。 - 简单性: 代码逻辑相对直观,符合“请求-处理-响应”的同步思维模式。
2. NIO (同步非阻塞 IO) - 代码与分析
核心特点: 基于 Selector 的事件驱动,一个线程管理多个连接,非阻塞 API。
// NioServer.java
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.Set;
public class NioServer {
public static void main(String[] args) throws IOException {
// 1. 创建 Selector,用于注册和监听 Channel 事件
Selector selector = Selector.open();
// 2. 创建 ServerSocketChannel,作为服务器监听端口
ServerSocketChannel serverChannel = ServerSocketChannel.open();
// 3. 绑定端口
serverChannel.bind(new InetSocketAddress(8080));
// 4. 【关键】设置为非阻塞模式,这样 accept() 不会阻塞
serverChannel.configureBlocking(false);
// 5. 【关键】将 ServerSocketChannel 注册到 Selector,
// 并指定感兴趣的事件是 OP_ACCEPT (接受连接事件)
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("NIO Server started on port 8080, waiting for events...");
while (true) { // 事件循环 (Event Loop)
// 6. 【关键】selector.select() 是一个【阻塞】方法 (但可以设置超时)
// 它会阻塞,直到至少有一个注册的 Channel 准备好进行所关注的 IO 操作
// 或者超时、或者被 selector.wakeup() 唤醒
if (selector.select() == 0) {
// select() 返回 0 表示没有 Channel 就绪 (例如超时或被唤醒)
continue;
}
// 7. 获取所有已就绪事件的 SelectionKey 集合
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
// 8. 遍历就绪的 Key
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
// 9. 根据 Key 的类型判断是哪种事件就绪
if (key.isAcceptable()) {
// a. 处理接受连接事件
handleAccept(key, selector);
} else if (key.isReadable()) {
// b. 处理读数据事件
handleRead(key);
}
// ... 可以添加 isWritable() 的处理逻辑 ...
// 10. 【非常重要】处理完一个 Key 后,必须将其从 selectedKeys 集合中移除
// 否则下次 select() 返回时,这个 Key 还在集合里,会重复处理
keyIterator.remove();
}
}
// 注意:实际应用中需要添加关闭 Selector 和 Channel 的逻辑
}
// 处理接受连接事件的方法
private static void handleAccept(SelectionKey key, Selector selector) throws IOException {
// 11. 从 Key 中获取关联的 ServerSocketChannel
ServerSocketChannel server = (ServerSocketChannel) key.channel();
// 12. 调用 accept() 接受连接,因为是非阻塞模式,会立刻返回
// 如果有连接则返回 SocketChannel,没有则返回 null
SocketChannel clientChannel = server.accept();
if (clientChannel != null) {
// 13. 【关键】将新接受的 SocketChannel 也设置为非阻塞模式
clientChannel.configureBlocking(false);
// 14. 【关键】将这个新的 SocketChannel 注册到【同一个】Selector 上
// 并指定感兴趣的事件是 OP_READ (读取数据事件)
// 可以将 ByteBuffer 作为附件关联到 Key 上,方便后续读写
clientChannel.register(selector, SelectionKey.OP_READ, ByteBuffer.allocate(1024));
System.out.println("Client connected: " + clientChannel.getRemoteAddress());
}
}
// 处理读数据事件的方法
private static void handleRead(SelectionKey key) throws IOException {
// 15. 从 Key 中获取关联的 SocketChannel
SocketChannel clientChannel = (SocketChannel) key.channel();
// 16. 从 Key 的附件中获取之前分配的 ByteBuffer (或者在这里创建)
ByteBuffer buffer = (ByteBuffer) key.attachment();
try {
// 17. 【关键】调用 read() 读取数据,因为是非阻塞模式,会立刻返回
// 返回值 > 0: 读取到数据
// 返回值 = 0: 当前没有数据可读
// 返回值 = -1: 连接已关闭
int bytesRead = clientChannel.read(buffer);
if (bytesRead > 0) {
// 18. 读取到数据,切换 Buffer 为读模式
buffer.flip();
// 19. 解码 Buffer 中的字节为字符串
String receivedMessage = StandardCharsets.UTF_8.decode(buffer).toString().trim();
System.out.println("Received from " + clientChannel.getRemoteAddress() + ": " + receivedMessage);
// 20. 准备回显的响应数据
String responseMessage = "Server received: " + receivedMessage;
ByteBuffer writeBuffer = StandardCharsets.UTF_8.encode(responseMessage);
// 21. 【关键】调用 write() 写回数据,也是非阻塞的
// 注意:write() 不保证一次性写完所有数据,可能需要处理 "写半包"
// 简单起见,这里假设能一次写完。复杂场景需要配合 OP_WRITE 事件。
clientChannel.write(writeBuffer);
// 22. 清空或压缩读 Buffer,为下次读取做准备
// buffer.clear(); // 或者 buffer.compact();
buffer.clear(); // 这里简单清空
} else if (bytesRead == -1) {
// 23. 客户端关闭连接
System.out.println("Client disconnected: " + clientChannel.getRemoteAddress());
key.cancel(); // 从 Selector 中注销该 Channel
clientChannel.close(); // 关闭 Channel
}
// bytesRead == 0 的情况不用处理,等待下次 select() 通知即可
} catch (IOException e) {
// 24. 发生 IO 异常,通常也表示连接出问题
System.err.println("Error handling read/write for " + clientChannel.getRemoteAddress() + ": " + e.getMessage());
key.cancel();
clientChannel.close();
}
}
}
// NIO Client 可以使用上面的 BioClient 进行测试,因为客户端行为是一样的。
NIO 代码分析:
- 非阻塞 API:
serverChannel.configureBlocking(false)和clientChannel.configureBlocking(false)是关键。这使得accept()和read()/write()不会阻塞线程。 - Selector: 核心组件。
register()告诉 Selector 要关注哪个 Channel 的什么事件。select()阻塞等待事件就绪。selectedKeys()获取就绪事件。 - 事件驱动: 整个流程由事件驱动。线程不再傻等某个特定操作,而是等待任何一个感兴趣的事件发生。
- 单线程管理多连接: 上述代码(除去业务处理的复杂性)可以用一个线程来运行
main方法中的while(true)循环,从而管理所有客户端连接的接受和读写事件。这是 NIO 相比 BIO 在伸缩性上的巨大优势。 - Buffer 操作: 数据读写必须通过
ByteBuffer。需要理解allocate,read,flip,decode,encode,write,clear等 Buffer 操作。 - 复杂度: 代码逻辑比 BIO 复杂得多,需要管理 Channel 状态、事件类型、Buffer 状态以及 Selector 的交互。
3. AIO (异步非阻塞 IO) - 代码与分析
核心特点: 应用发起 IO 操作后不等待,由操作系统完成 IO 后回调通知应用。真正的异步。
// AioServer.java
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.StandardSocketOptions;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.nio.charset.StandardCharsets;
import java.util.concurrent.CompletionHandler;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class AioServer {
private AsynchronousServerSocketChannel serverChannel;
private ExecutorService executorService; // 用于执行回调的线程池
public void start(int port) throws IOException {
executorService = Executors.newCachedThreadPool();
// 1. 创建 AsynchronousChannelGroup,管理共享资源,如线程池
AsynchronousChannelGroup group = AsynchronousChannelGroup.withCachedThreadPool(executorService, 1);
// 2. 创建 AsynchronousServerSocketChannel
serverChannel = AsynchronousServerSocketChannel.open(group);
// 设置一些选项 (可选)
serverChannel.setOption(StandardSocketOptions.SO_REUSEADDR, true);
// 3. 绑定端口
serverChannel.bind(new InetSocketAddress(port));
System.out.println("AIO Server started on port " + port + ", waiting for connections...");
// 4. 【关键】发起【异步】accept 操作
// 第一个参数 attachment: 可以在回调时传递的附加对象,这里是 null
// 第二个参数 handler: 操作完成(成功或失败)后的回调处理器
// 这个 accept() 方法会【立刻返回】,不会阻塞
serverChannel.accept(null, new AcceptCompletionHandler());
}
// 接受连接的回调处理器
private class AcceptCompletionHandler implements CompletionHandler<AsynchronousSocketChannel, Void> {
@Override
public void completed(AsynchronousSocketChannel clientChannel, Void attachment) {
// 5. 【回调】当一个连接成功接受时,这个方法会被【某个线程】调用
try {
System.out.println("Client connected: " + clientChannel.getRemoteAddress());
} catch (IOException e) {
System.err.println("Error getting remote address: " + e.getMessage());
}
// 6. 【关键】为了能持续接受下一个连接,必须再次调用 accept
// 将 this (当前 Handler 对象) 作为 handler,形成链式调用
serverChannel.accept(null, this);
// 7. 为新连接准备读操作
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 8. 创建一个包含 Channel 和 Buffer 的上下文对象,方便在回调中传递
ClientContext context = new ClientContext(clientChannel, buffer);
// 9. 【关键】发起【异步】read 操作
// 将 buffer 和 context 作为 attachment 传递给回调
// 这个 read() 方法也会【立刻返回】
clientChannel.read(buffer, context, new ReadCompletionHandler());
}
@Override
public void failed(Throwable exc, Void attachment) {
// 10. 【回调】当接受连接操作失败时,这个方法会被调用
System.err.println("Accept failed: " + exc.getMessage());
// 可能需要记录日志或尝试重新启动监听
}
}
// 客户端读写上下文
private static class ClientContext {
AsynchronousSocketChannel channel;
ByteBuffer buffer;
ClientContext(AsynchronousSocketChannel channel, ByteBuffer buffer) {
this.channel = channel;
this.buffer = buffer;
}
}
// 读取数据的回调处理器
private class ReadCompletionHandler implements CompletionHandler<Integer, ClientContext> {
@Override
public void completed(Integer bytesRead, ClientContext context) {
// 11. 【回调】当读取操作成功完成时,这个方法会被调用
// bytesRead: 实际读取到的字节数 (-1 表示连接关闭)
// context: 发起 read 时传入的上下文对象
if (bytesRead > 0) {
// 12. 读取到数据,切换 Buffer 为读模式
context.buffer.flip();
String receivedMessage = StandardCharsets.UTF_8.decode(context.buffer).toString().trim();
try {
System.out.println("Received from " + context.channel.getRemoteAddress() + ": " + receivedMessage);
} catch (IOException e) { /* ignore */ }
// 13. 准备回显数据
String responseMessage = "Server received: " + receivedMessage;
ByteBuffer writeBuffer = StandardCharsets.UTF_8.encode(responseMessage);
// 14. 【关键】发起【异步】write 操作
// 将 writeBuffer 和 context 作为 attachment 传递
context.channel.write(writeBuffer, context, new WriteCompletionHandler());
// 15. 清空读 Buffer 为下次读做准备 (放在这里或 Write 完成后都可以)
context.buffer.clear();
} else if (bytesRead == -1) {
// 16. 客户端关闭连接
handleDisconnection(context.channel);
}
// bytesRead == 0: 异步模型通常不会是 0,除非 buffer 满了?(一般不用特别处理)
}
@Override
public void failed(Throwable exc, ClientContext context) {
// 17. 【回调】当读取操作失败时,这个方法会被调用
handleFailure("Read failed", exc, context.channel);
}
}
// 写入数据的回调处理器
private class WriteCompletionHandler implements CompletionHandler<Integer, ClientContext> {
@Override
public void completed(Integer bytesWritten, ClientContext context) {
// 18. 【回调】当写入操作成功完成时,这个方法会被调用
// 注意:bytesWritten 可能小于要写入的总字节数,表示只写了一部分
// 19. 获取 write 时传入的 ByteBuffer (它可能还在 context 里,或者就是传入的 writeBuffer)
// (这里假设 Write 时传入的是待写入的 buffer,需要从 attachment 获取)
// 为了简化,我们假设 write 时传入的 attachment 是包含 write buffer 的对象,
// 或者像 read 那样,write 时第一个参数就是 buffer,第二个是 context
// 我们直接依赖 Read Handler 中发起的 Write,并在完成后准备下次 Read
// 20. 写入完成后,发起下一次【异步】read 操作,形成闭环
// 注意:复杂应用可能需要检查是否完全写入,如果没写完要继续 write
context.channel.read(context.buffer, context, new ReadCompletionHandler());
}
@Override
public void failed(Throwable exc, ClientContext context) {
// 21. 【回调】当写入操作失败时,这个方法会被调用
handleFailure("Write failed", exc, context.channel);
}
}
// 统一处理失败和断开连接
private void handleFailure(String message, Throwable exc, AsynchronousSocketChannel channel) {
try {
System.err.println(message + " for " + channel.getRemoteAddress() + ": " + exc.getMessage());
if (channel.isOpen()) channel.close();
} catch (IOException e) { /* ignore close exception */ }
}
private void handleDisconnection(AsynchronousSocketChannel channel) {
try {
System.out.println("Client disconnected: " + channel.getRemoteAddress());
if (channel.isOpen()) channel.close();
} catch (IOException e) { /* ignore close exception */ }
}
public void stop() {
try {
if (serverChannel != null) serverChannel.close();
} catch (IOException e) { /* ignore */ }
if (executorService != null) executorService.shutdown();
try {
if (executorService != null && !executorService.awaitTermination(5, TimeUnit.SECONDS)) {
executorService.shutdownNow();
}
} catch (InterruptedException e) {
executorService.shutdownNow();
Thread.currentThread().interrupt();
}
System.out.println("AIO Server stopped.");
}
public static void main(String[] args) {
AioServer server = new AioServer();
try {
server.start(8080);
// 让主线程保持运行,否则程序会退出
Thread.currentThread().join();
} catch (IOException | InterruptedException e) {
e.printStackTrace();
server.stop();
}
}
}
// AIO Client 可以使用上面的 BioClient 进行测试
AIO 代码分析:
- 异步 API: 使用
AsynchronousServerSocketChannel和AsynchronousSocketChannel。核心方法如accept(),read(),write()都会立即返回,并且需要提供一个CompletionHandler对象。 - CompletionHandler: 这是 AIO 的核心。你需要为每个异步操作(接受、读、写)定义一个处理器,其中包含
completed()和failed()两个方法。当操作系统完成相应的 IO 操作后,会自动调用这两个方法之一。 - 回调驱动: 整个程序的流程由回调函数驱动。一个操作完成后,在它的
completed()回调中发起下一个操作(比如accept完成后发起read,read完成后发起write,write完成后发起下一次read),形成一个异步链条。 - 线程模型: 发起 IO 操作的线程(比如
main线程或AcceptCompletionHandler所在的线程)不会等待 IO 完成。IO 操作由操作系统在后台完成,完成后,操作系统会通知 Java 运行时,运行时会从AsynchronousChannelGroup关联的线程池中取一个线程来执行你的CompletionHandler。这意味着处理 IO 结果的线程可能与发起 IO 的线程不同。 - 复杂度: 编程模型与同步模型差异很大,需要适应基于回调的异步思维。管理回调、状态传递(通过
attachment)可能比较复杂,容易出现“回调地狱”。
IO 多路复用 (技术层面):
IO 多路复用本身是一种操作系统技术,没有直接对应的 Java 代码“模型”像 BIO/NIO/AIO 那样。但 NIO 的 Selector 就是对 IO 多路复用技术的 Java 封装。因此,NIO Server 的代码示例实际上就展示了如何在 Java 中使用 IO 多路复用技术。
关键点在于:
- 注册多个 Channel 到一个 Selector:
serverChannel.register(selector, ...)和clientChannel.register(selector, ...)。 - 调用
select()阻塞等待:selector.select()这一步,底层就是依赖操作系统的select/poll/epoll等机制来等待多个 Channel 中的任意一个就绪。 - 处理就绪的 Channel: 遍历
selectedKeys并对每个key对应的 Channel 执行非阻塞的 IO 操作。
所以,理解了 NIO Server 的代码,尤其是 Selector 的使用,你就理解了如何在 Java 应用层面利用 IO 多路复用技术。
附录
单线程 Reactor 模式
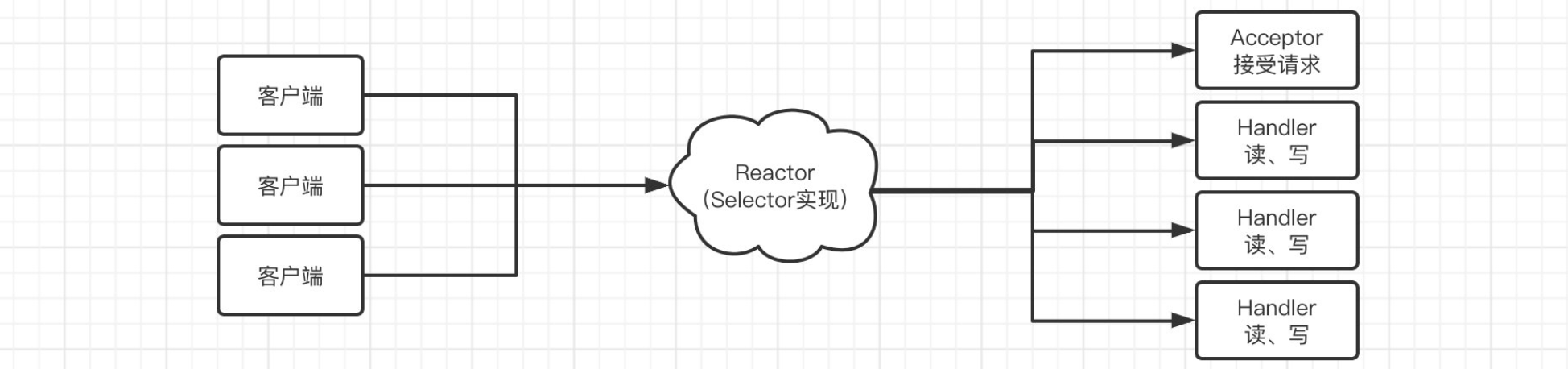
graph TD
subgraph Single Thread
R[Reactor] -- 1.register --> S(Selector)
C1[Channel 1 ServerSocket] -- OP_ACCEPT --> S
C2[Channel 2 Socket] -- OP_READ/WRITE --> S
C3[Channel 3 Socket] -- OP_READ/WRITE --> S
R -- 2.select() --> S
S -- 3.notifies SelectionKeys --> R
R -- 4.dispatch Accept --> H_Accept(Acceptor Handler)
R -- 4.dispatch Read/Write --> H_RW(Read/Write Handler)
H_Accept -- 5.performs accept & registers new channel --> S
H_RW -- 5.performs read/write --> C2/C3
end
style R fill:#f9f,stroke:#333,stroke-width:2px
style S fill:#ccf,stroke:#333,stroke-width:1px
style H_Accept fill:#9cf,stroke:#333,stroke-width:1px
style H_RW fill:#9fc,stroke:#333,stroke-width:1px多线程 Reactor (Worker Pool)
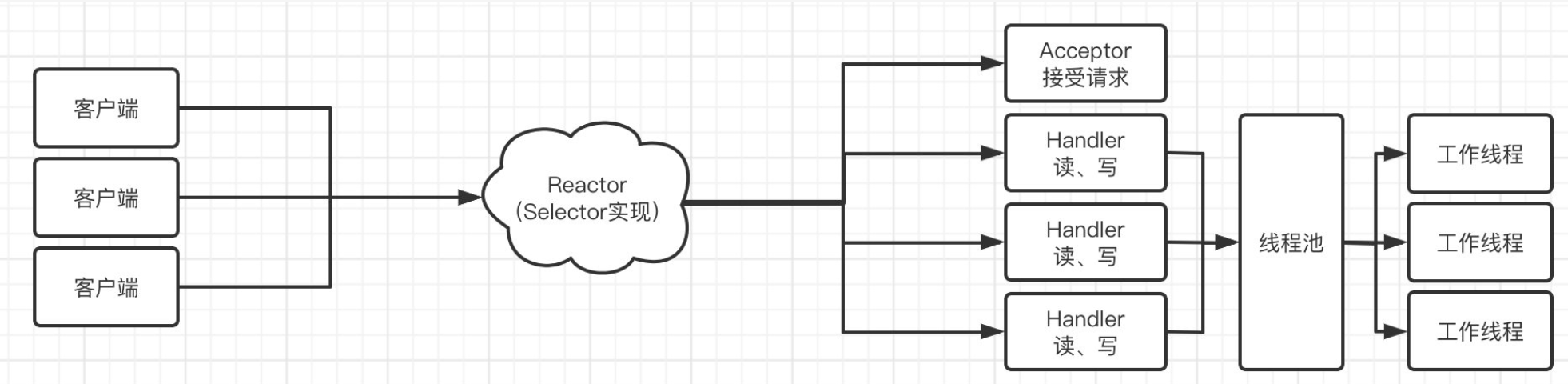
graph TD
subgraph Reactor Thread
R[Reactor] -- 1.register --> S(Selector)
C1[Channel 1 ServerSocket] -- OP_ACCEPT --> S
C2[Channel 2 Socket] -- OP_READ --> S
C3[Channel 3 Socket] -- OP_READ --> S
R -- 2.select() --> S
S -- 3.notifies SelectionKeys --> R
R -- 4.dispatch Accept --> H_Accept(Acceptor Handler)
R -- 4.dispatches Read IO Only --> H_IO(IO Handler Reader)
H_Accept -- 5.performs accept & registers new channel --> S
H_IO -- 5.reads data --> Buffer[ByteBuffer]
H_IO -- 6.submits task --> WP(Worker Thread Pool)
end
subgraph Worker Threads
WP -- 7.assigns task --> T1(Handler Thread 1)
WP -- 7.assigns task --> T2(Handler Thread 2)
T1 -- 8.processes Buffer & prepares response --> Resp1[Response Buffer]
T2 -- 8.processes Buffer & prepares response --> Resp2[Response Buffer]
T1 -- 9.May schedule write back via Reactor/Selector --> R
T2 -- 9.May schedule write back via Reactor/Selector --> R
end
style R fill:#f9f,stroke:#333,stroke-width:2px
style S fill:#ccf,stroke:#333,stroke-width:1px
style H_Accept fill:#9cf,stroke:#333,stroke-width:1px
style H_IO fill:#9fc,stroke:#333,stroke-width:1px
style WP fill:#fec,stroke:#333,stroke-width:2px主从 Reactor (Main-Sub Reactor)
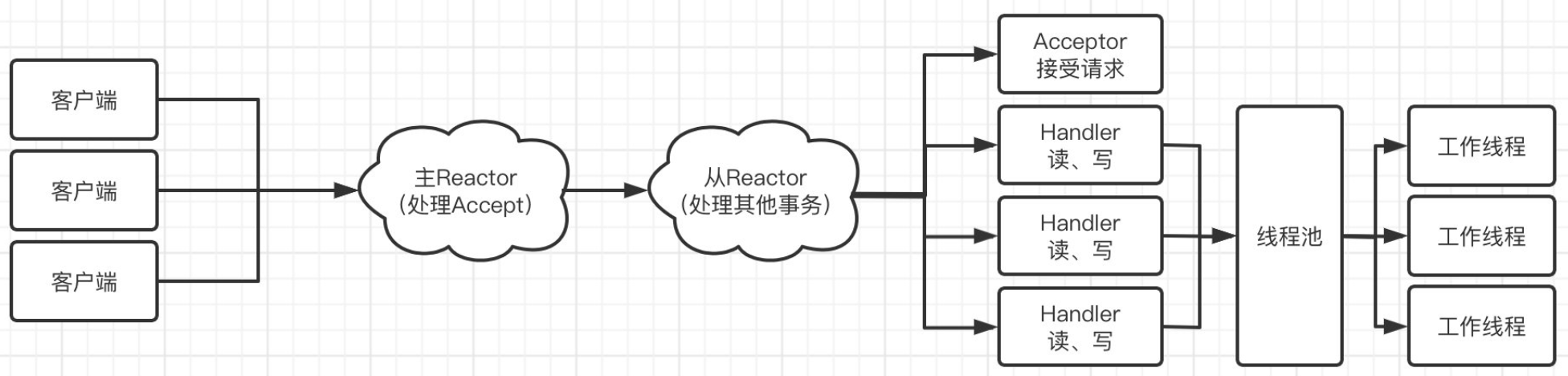
graph TD
subgraph Main Reactor Thread
MR[Main Reactor] -- 1.register --> MS(Main Selector)
SSC[ServerSocketChannel] -- OP_ACCEPT --> MS
MR -- 2.select() --> MS
MS -- 3.notifies Accept --> MR
MR -- 4.dispatches Accept --> MA(Acceptor)
MA -- 5.performs accept --> NewSC(New SocketChannel)
MA -- 6.selects SubReactor & registers NewSC --> SR1_S(SubReactor 1 Selector)
MA -- 6.selects SubReactor & registers NewSC --> SR2_S(SubReactor 2 Selector)
end
subgraph Sub Reactor Thread 1
SR1[SubReactor 1] -- register --> SR1_S
C1[SocketChannel 1] -- OP_READ/WRITE --> SR1_S
C3[SocketChannel 3] -- OP_READ/WRITE --> SR1_S
SR1 -- select() --> SR1_S
SR1_S -- notifies Read/Write --> SR1
SR1 -- dispatches Read/Write --> H_RW1(Read/Write Handler 1)
H_RW1 -- performs IO & processing --> C1/C3
end
subgraph Sub Reactor Thread 2
SR2[SubReactor 2] -- register --> SR2_S
C2[SocketChannel 2] -- OP_READ/WRITE --> SR2_S
C4[SocketChannel 4] -- OP_READ/WRITE --> SR2_S
SR2 -- select() --> SR2_S
SR2_S -- notifies Read/Write --> SR2
SR2 -- dispatches Read/Write --> H_RW2(Read/Write Handler 2)
H_RW2 -- performs IO & processing --> C2/C4
end
style MR fill:#f9f,stroke:#333,stroke-width:2px
style MS fill:#ccf,stroke:#333,stroke-width:1px
style MA fill:#9cf,stroke:#333,stroke-width:1px
style SR1 fill:#f9f,stroke:#333,stroke-width:2px
style SR2 fill:#f9f,stroke:#333,stroke-width:2px
style SR1_S fill:#ccf,stroke:#333,stroke-width:1px
style SR2_S fill:#ccf,stroke:#333,stroke-width:1px
style H_RW1 fill:#9fc,stroke:#333,stroke-width:1px
style H_RW2 fill:#9fc,stroke:#333,stroke-width:1px